

mysql中文首字母排序或搜索
1:按照中文的首字母排序的实现方式:
方式1:改字段的字符集为gbk:
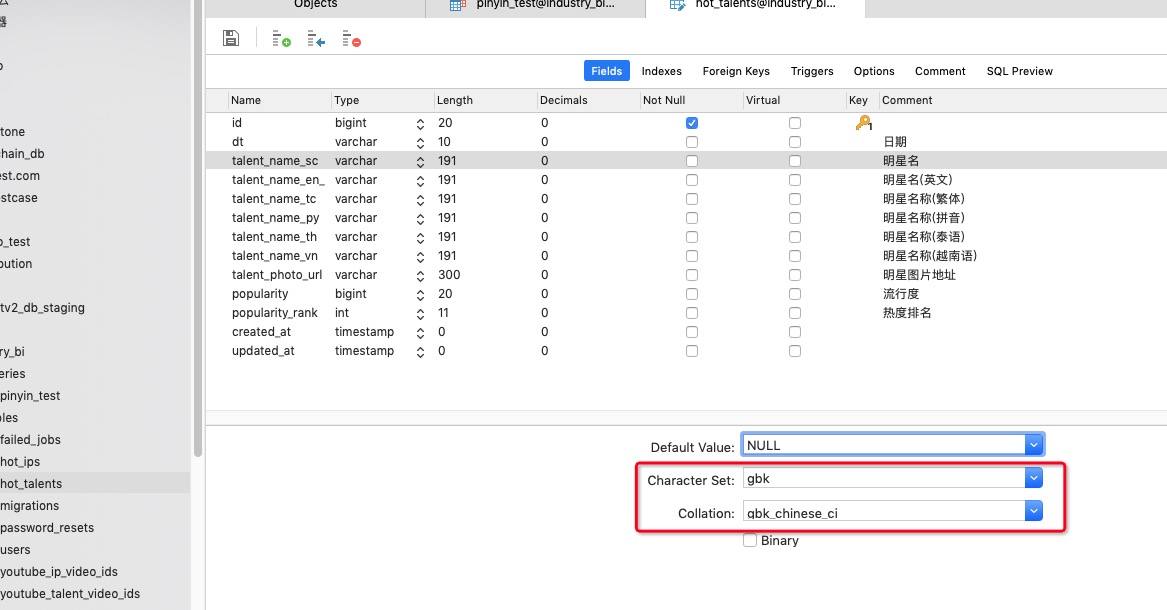
查询时orderBy的字段保持不变:
$this->validate($request, [
'sortBy' => 'filled|string',
'sortType' => 'filled|string|in:' . config('global.sort_type_desc') . ',' . config('global.sort_type_asc'),
]);
$sortBy = $request->sortBy ?? HotTalent::SORT_BY_POPULARITY_RANK;
$sortType = $request->sortType ?? config('global.sort_type_asc');
$date = Carbon::yesterday()->subDay(4)->toDateString();
$date = str_replace('-', '', $date);
$hot_talents = HotTalent::where('dt', $date)
->orderBy($sortBy, $sortType)
->get();
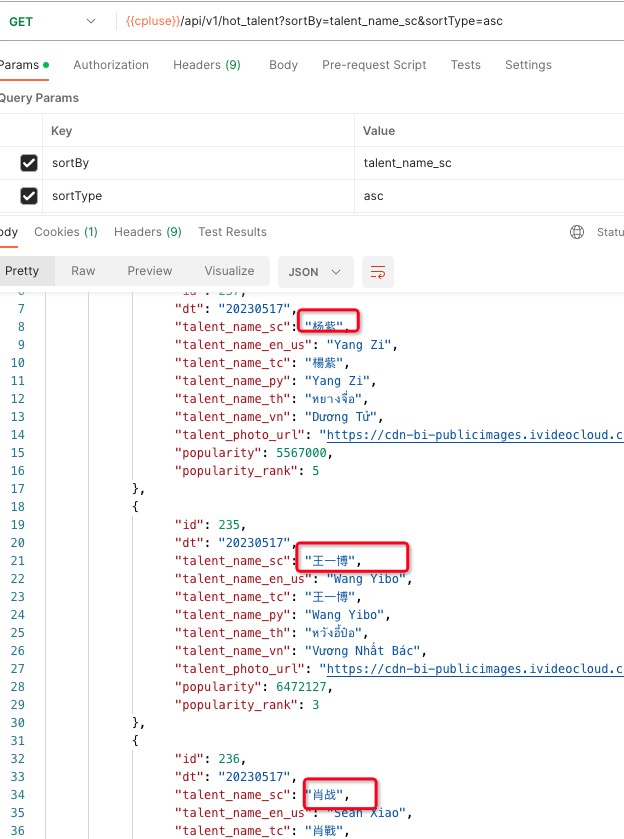
方法2:字符集保持不变为utf8,但要改查询时的字符集为gbk:
$this->validate($request, [
'sortBy' => 'filled|string',
'sortType' => 'filled|string|in:' . config('global.sort_type_desc') . ',' . config('global.sort_type_asc'),
]);
$sortBy = $request->sortBy ?? HotTalent::SORT_BY_POPULARITY_RANK;
$sortType = $request->sortType ?? config('global.sort_type_asc');
$date = Carbon::yesterday()->subDay(4)->toDateString();
$date = str_replace('-', '', $date);
$hot_talents = HotTalent::select('*')->where('dt', $date)
->orderBy(DB::raw("convert($sortBy using gbk)"), $sortType)
->get();
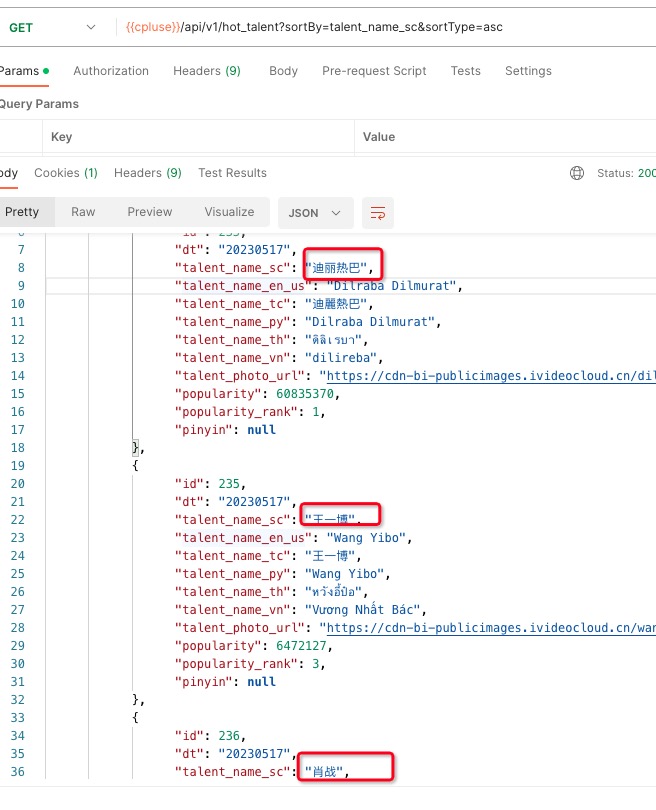
查询结果示例:
2:按照中文首字母搜索:
2.1:定义一个function:
CREATE FUNCTION `get_chinese_initials`(in_string VARCHAR(255)) RETURNS VARCHAR(255) CHARSET utf8
NO SQL
BEGIN
DECLARE tmp_str VARCHAR(255) CHARSET gbk DEFAULT '' ;
DECLARE tmp_len SMALLINT DEFAULT 0;
DECLARE tmp_loc SMALLINT DEFAULT 0;
DECLARE tmp_char VARCHAR(2) CHARSET gbk DEFAULT '';
DECLARE tmp_rs VARCHAR(255)CHARSET gbk DEFAULT '';
DECLARE tmp_cc VARCHAR(2) CHARSET gbk DEFAULT '';
SET tmp_str = in_string;
SET tmp_len = LENGTH(tmp_str);
WHILE tmp_len > 0 DO
SET tmp_char = LEFT(tmp_str,1);
SET tmp_cc = tmp_char;
#获取字符的编码范围的位置,为了确认汉字拼音首字母是那一个
SET tmp_loc=INTERVAL(CONV(HEX(tmp_char),16,10),0xB0A1,0xB0C5,0xB2C1,0xB4EE,0xB6EA,0xB7A2,0xB8C1,0xB9FE,0xBBF7,0xBFA6,0xC0AC
,0xC2E8,0xC4C3,0xC5B6,0xC5BE,0xC6DA,0xC8BB,0xC8F6,0xCBFA,0xCDDA ,0xCEF4,0xD1B9,0xD4D1);
#判断左端首个字符是多字节还是单字节字符,要是多字节则认为是汉字且作以下拼音获取,要是单字节则不处理。如果是多字节字符但是不在对应的编码范围之内,即对应的不是大写字母则也不做处理,这样数字或者特殊字符就保持原样了
IF (LENGTH(tmp_char)>1 AND tmp_loc>0 AND tmp_loc<24) THEN
#获得汉字拼音首字符
SELECT ELT(tmp_loc,'A','B','C','D','E','F','G','H','J','K','L','M','N','O','P','Q','R','S','T','W','X','Y','Z') INTO tmp_cc;
END IF;
#将当前tmp_str左端首个字符拼音首字符与返回字符串拼接
SET tmp_rs = CONCAT(tmp_rs,tmp_cc);
#将tmp_str左端首字符去除
SET tmp_str = SUBSTRING(tmp_str,2);
#计算当前字符串长度
SET tmp_len = LENGTH(tmp_str);
END WHILE;
RETURN tmp_rs;
END;
2.2:查询时调用自定义方法get_chinese_initials的字段:
$this->validate($request, [
'sortBy' => 'filled|string',
'sortType' => 'filled|string|in:' . config('global.sort_type_desc') . ',' . config('global.sort_type_asc'),
]);
$sortBy = $request->sortBy ?? HotTalent::SORT_BY_POPULARITY_RANK;
$sortType = $request->sortType ?? config('global.sort_type_asc');
$date = Carbon::yesterday()->subDay(4)->toDateString();
$date = str_replace('-', '', $date);
$search = $request->search;
$hot_talents = HotTalent::where('dt', $date)
->where(function ($q) use ($search) {
$q->where(DB::raw("get_chinese_initials(talent_name_sc)"), 'like', $search.'%');
})
->orderBy(DB::raw("convert($sortBy using gbk)"), 'asc')
->get();
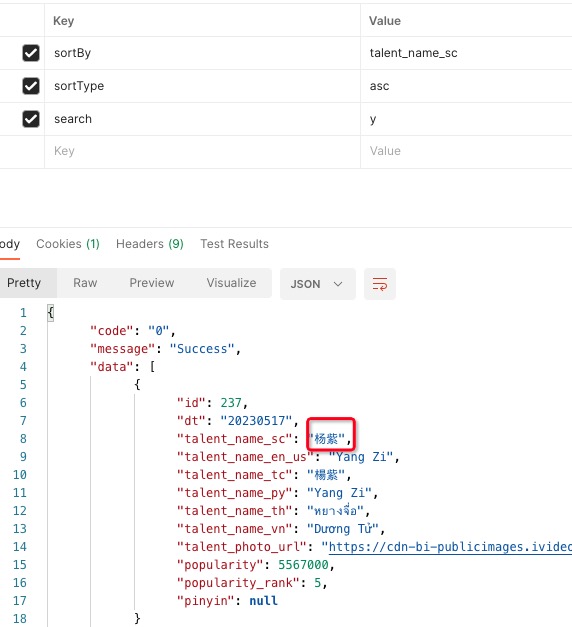
查询结果示例:
参考链接: https://blog.51cto.com/u_15460202/4811944